python读取通达信每日数据和五分钟数据,并且上传到clickhouse |
您所在的位置:网站首页 › 编译内容解析错误 通达信 › python读取通达信每日数据和五分钟数据,并且上传到clickhouse |
python读取通达信每日数据和五分钟数据,并且上传到clickhouse
|
python读取通达信每日数据和五分钟数据,并且上传到clickhouse
本文主要是借助txd和python实现数据下载,并上传到数据库,实现高效的数据查询和统计 通达信读取五分钟数据通达信将分钟数据文件.lc 转换为cvs格式,这里可以通过Dbeaver直接导入cvs格式文件,转换代码在下面,导入后是多个文件夹,表名为股票代码
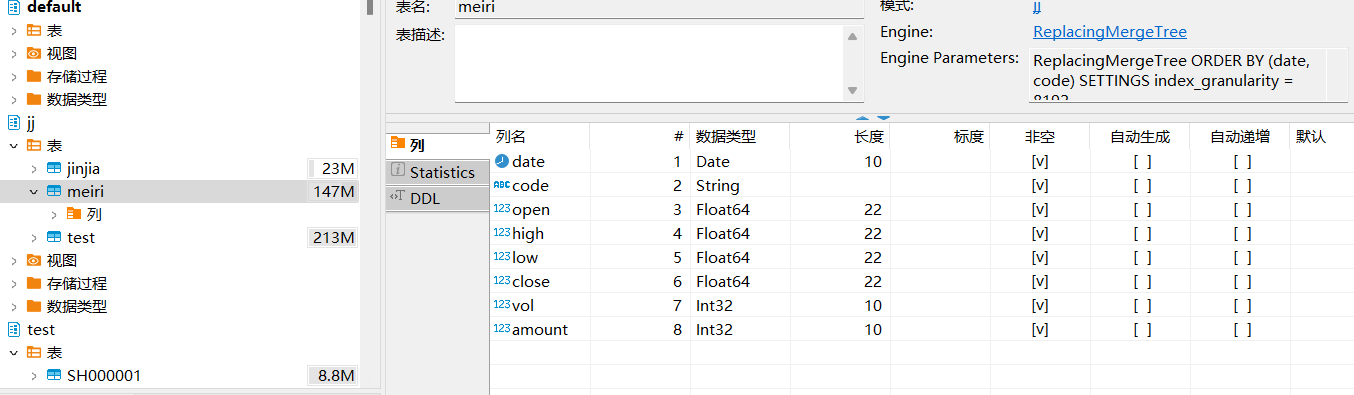
吞吐量可以使用每秒处理的行数或每秒处理的字节数来衡量。如果数据被放置在page cache中,则一个不太复杂的查询在单个服务器上大约能够以2-10GB/s(未压缩)的速度进行处理(对于简单的查询,速度可以达到30GB/s)。如果数据没有在page cache中的话,那么速度将取决于你的磁盘系统和数据的压缩率。例如,如果一个磁盘允许以400MB/s的速度读取数据,并且数据压缩率是3,则数据的处理速度为1.2GB/s。这意味着,如果你是在提取一个10字节的列,那么它的处理速度大约是1-2亿行每秒。 对于分布式处理,处理速度几乎是线性扩展的,但这受限于聚合或排序的结果不是那么大的情况下。 处理短查询的延迟时间如果一个查询使用主键并且没有太多行(几十万)进行处理,并且没有查询太多的列,那么在数据被page cache缓存的情况下,它的延迟应该小于50毫秒(在最佳的情况下应该小于10毫秒)。 否则,延迟取决于数据的查找次数。如果你当前使用的是HDD,在数据没有加载的情况下,查询所需要的延迟可以通过以下公式计算得知: 查找时间(10 ms) * 查询的列的数量 * 查询的数据块的数量。 处理大量短查询的吞吐量在相同的情况下,ClickHouse可以在单个服务器上每秒处理数百个查询(在最佳的情况下最多可以处理数千个)。但是由于这不适用于分析型场景。因此我们建议每秒最多查询100次。 数据的写入性能我们建议每次写入不少于1000行的批量写入,或每秒不超过一个写入请求。当使用tab-separated格式将一份数据写入到MergeTree表中时,写入速度大约为50到200MB/s。如果您写入的数据每行为1Kb,那么写入的速度为50,000到200,000行每秒。如果您的行更小,那么写入速度将更高。为了提高写入性能,您可以使用多个INSERT进行并行写入,这将带来线性的性能提升。 ReplacingMergeTree引擎该引擎和 MergeTree 的不同之处在于它会删除排序键值相同的重复项。 数据的去重只会在数据合并期间进行。合并会在后台一个不确定的时间进行,因此你无法预先作出计划。有一些数据可能仍未被处理。尽管你可以调用 OPTIMIZE 语句发起计划外的合并,但请不要依靠它,因为 OPTIMIZE 语句会引发对数据的大量读写。 因此,ReplacingMergeTree 适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现。挺适合股票分析,因此主要用这个 搭建过程安装 | ClickHouse Docs 请直接参考官方文件,里面有详细的描述,另外,数据大约为40g,历史的五分钟数据和day数据,我用的是腾讯云服务器 数据上传代码 from clickhouse_driver import Client import re from tqdm import tqdm import os import pandas as pd import user_config as ucfg client = Client('ip',database='jj', user='c',password='password',settings={"use_numpy":True}) file_list = os.listdir(ucfg.tdx['csv_lday']) tq = tqdm(file_list, leave=False, position=None) for filename in tq: df=pd.read_csv('D:\TDXdata\lday_qfq\\'+filename) df['date']=df['date'].apply(str) df['code']=df['code'].apply(str) #client.execute('DROP TABLE IF EXISTS test') client.execute('CREATE TABLE IF NOT EXISTS meiri ( `date` Date, `code` String, `open` Float64,`high` Float64,`low` Float64,`close` Float64,`vol` Int32, `amount` Int32) ENGINE = ReplacingMergeTree ORDER BY (date,code)') client.insert_dataframe('INSERT INTO meiri VALUES', df)这里是每日的上传代码,上传后结果如下图所示
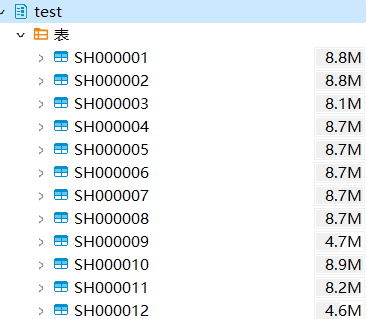
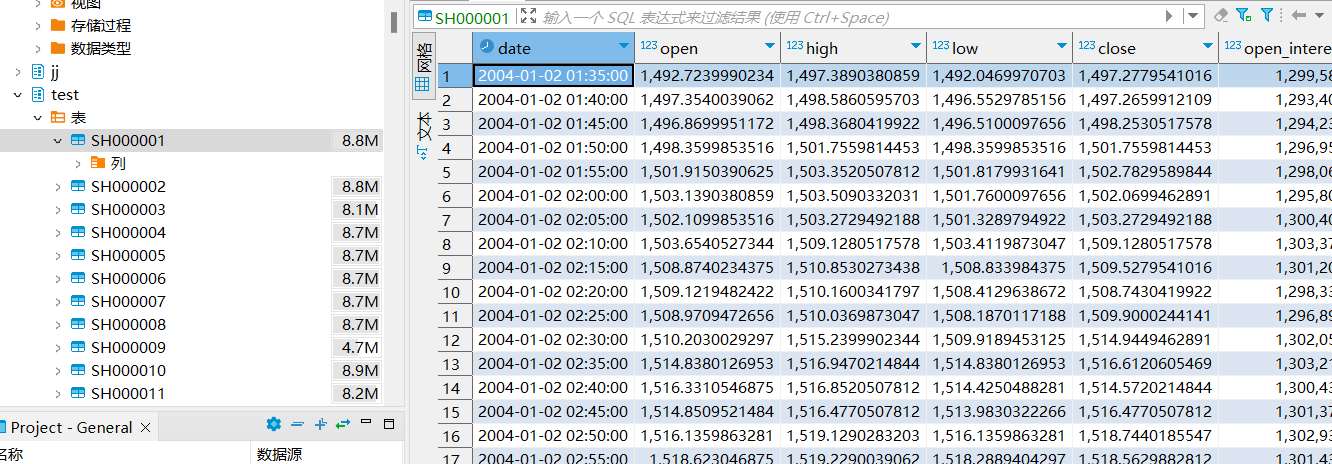
五分钟的代码下载链接如下:https://download.csdn.net/download/CBLXXX/87418923 历史的五分钟数据一般在tdx所属目录下面,建议自己去具体看一下,注意,通达信和很多方式一样无法获取所有的历史数据,建议通过类似tushare的方式获取 数据包含tdx,自2005年到2022年数据,最新的数据可以直接下载,通达信有下载时间的限制,同样akshare也有下载时间的限制 上传后,将以股票代码为表名
股票分析: 使用python进行股票分析和选股 (gitee.com) |
【本文地址】